Mật mã Vigenère là một phương pháp mã hóa chữ văn bản tiếng Anh, lần đầu tiên được mô tả bởi Giovan Battista Bellaso vào năm 1553. Phương pháp mã hóa mật mã Vigenère dễ hiểu và dễ thực hiện, nhưng chỉ đến năm 1863 với nhiều nỗ lực suốt ba thế kỷ, Friedrich Kasiski mới xuất bản một phương pháp chung để giải mã mật mã Vigenère.
Mật mã Vigenère là tập hợp các quy tắc thay thế chữ cái đơn trong bảng chữ cái tiếng Anh qua việc sử dụng 26 mật mã Caesar với các bước dịch chuyển từ 0 đến 25 tương ứng từ chữ ‘a’ đến chữ ‘z’. Cụ thể, bản mã Vigenère được lập theo công thức sau:
ci = (pi + ki) mod 26, i=1,…,l
trong đó, C = {c1…cl} là bản mã, P={p1…pl} là bản gốc, K = {k1…kl} là dãy khóa và l là độ dài bản rõ. Tương tự, bản gốc P có thể được tính nếu biết khóa và bản mã theo công thức:
pj = (cj – kj) mod 26, j = 1,…,l
Mật mã Vigenère không thể phá vỡ trong trường hợp sử dụng các khóa đủ dài. Nhưng với các khóa ngắn hoặc nếu nhà thám mã có đủ nhiều bản mã so với độ dài khóa thì khá dễ để phá vỡ. Việc thám mật mã Vigenère thường tiến hành theo hai bước là: xác định độ dài chu kỳ của khóa trước, sau đó tìm khóa cụ thể.
Đầu tiên cần lưu ý là chu kỳ của khóa tìm được có thể không đúng với thực tế được sử dụng. Nếu bản mã đủ dài thì có thể là chính xác, các phương pháp được cung cấp ở đây là gần đúng.
Mật mã Vigenère áp dụng các mật mã Caesar khác nhau cho các chữ cái liên tiếp. Ví dụ một bản mã Vigenère như sau:

Hình 1. Bản mã hóa sử dụng mật mã Vigenère
Mật mã Caesar là một dạng của mật mã thay thế, theo đó mỗi ký tự trong bản rõ được thay thế bằng một ký tự cách nó một đoạn trong bảng chữ cái để tạo thành bản mã. Giả sử với khóa là 3 (dịch 3 vị trí trong bảng chữ cái), thì chữ ‘a’ sẽ được thay bằng chữ ‘d’, chữ ‘b’ sẽ được thay bằng ‘e’ và cứ thế đến hết bản rõ. Phương pháp này được đặt tên là Caesar, vị Hoàng đế đã sử dụng loại mật mã này thường xuyên trong công việc.
Nếu mật mã Vigenère sử dụng khóa có chu kỳ 3 là 'PUB', thì chữ cái rõ đầu tiên được mã hóa bằng mật mã Caesar với khóa là 16 (P là chữ cái thứ 16 của bảng chữ cái), chữ cái thứ hai được mã với khóa là 21 (chữ cái U) và chữ cái thứ ba được mã với khóa là 2 (chữ cái B). Chữ cái rõ thứ 4 được mã hóa quay lại bằng chữ khóa thứ nhất (khóa 16). Kết quả là, các chữ cái ở các vị trí 1,4,7,10,... đều được mã hóa bằng cùng một mật mã Caesar với chữ khóa là P. Các chữ cái ở các vị trí 2,5,8,11,... và 3,6,9,12,... được mã hóa bằng mật mã Caesar với khóa tương ứng là chữ U và B.
Như vậy, trình tự chính xác sẽ phụ thuộc vào chu kỳ của khóa mật mã, tức là độ dài khóa, như với ví dụ trên thì độ dài chu kỳ khóa là 3.
Để xác định chu kỳ của khóa mật mã Vigenère, phương pháp Kasiski xem xét sự lặp lại của các nhóm chữ cái như Hình 2.

Hình 2. Sự lặp lại của nhóm chữ cái
Đoạn lặp lại loạt VHVS gồm 18 ký tự, gợi ý rằng độ dài khóa có thể là 18, 9, 6, 3, 2. Còn đoạn lặp lại loạt QUCE là 30 ký tự, gợi ý độ dài khóa là 30, 15, 10, 6, 5, 3, 2. Kết hợp lại, độ dài khóa có thể là 6, 3 hoặc 2.
Nếu trong bản mã không có sự lặp lại của một loạt chữ cái nào, người thám mã sẽ sử dụng đến chỉ số trùng hợp Ic.
Giả sử X là một chuỗi ký tự trong tiếng Anh, ký hiệu xác suất xuất hiện của các chữ a, b,…, z lần lượt là p0, p1,…, p25. Khi đó:
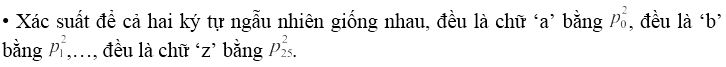
• Khi đó:
Ic (x) = ∑ = 0.0822+0.0152+…+0.0012 = 0.065
Chỉ số trùng hợp đôi khi được gọi là tỷ lệ lặp lại. Nếu bản mã cụ thể có độ dài n, na là tần số xuất hiện của chữ ‘a’, nb là tần số xuất hiện của chữ ‘b’…, thì chỉ số trùng hợp gần đúng được tính theo công thức sau:
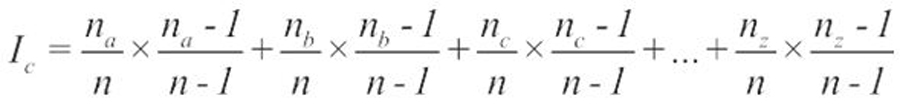
Chỉ số trùng hợp (Ic) là một kỹ thuật thống kê giúp xác định một đoạn văn bản có đáp ứng quy luật ngôn ngữ của tiếng Anh. Một tính chất quan trọng của kỹ thuật là giá trị Ic không thay đổi nếu áp dụng mật mã thay thế đơn cho văn bản. Điều này là do Ic dựa trên tần số xuất hiện của chữ cái và mật mã thay thế đơn không làm thay đổi tần số của bộ chữ cái riêng lẻ. Với văn bản tiếng Anh sẽ có giá trị Ic làm tròn là 0.06, nếu các ký tự có phân phối đồng đều thì Ic gần hơn với 0,03 - 0,04.
Phương pháp dùng chỉ số trùng hợp để xác định chu kỳ của khóa mật mã Vigenère thực hiện như sau. Trước tiên, giả sử độ dài khóa là 2, thực hành trích xuất hai chuỗi tại các vị trí 1, 3, 5, 7,... và 2, 4, 6, 8,... từ bản mã như Hình 1 (lưu ý rằng Ic được tính bằng cách sử dụng toàn bộ chuỗi mã, không chỉ là phần được hiển thị).

Tương tự với trường hợp độ dài khóa là 3 sẽ có 3 chuỗi, tương ứng với các giá trị Ic như sau:

Như vậy, Ic trung bình đối với trường hợp chu kỳ 2 là khoảng 0,048 và đối với trường hợp chu kỳ 3 là khoảng 0,047.
Quy trình này sẽ được lặp lại cho tất cả các độ dài khóa muốn kiểm tra. Ví dụ tiếp tục tính với chu kỳ khóa lên đến 15 sẽ có các giá trị trung bình I.C (avg I.C.) tương ứng như Hình 3.
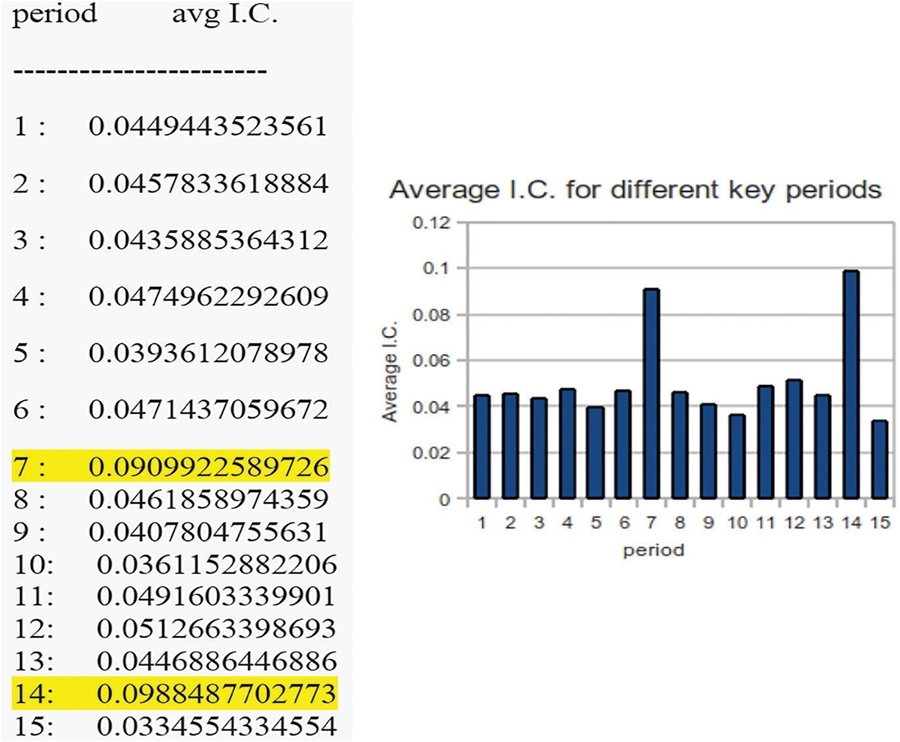
Hình 3. Các giá trị trung bình I.C.
Theo cột giá trị, hoặc theo biểu đồ, có 2 giá trị trung bình I.C cao đột biến đã gợi ý rằng khóa mật mã có thể có độ dài 7 hoặc 14. Cả hai xác suất này phải được tiếp tục kiểm tra.
Ví dụ thám mã với khóa chu kỳ 7 (sử dụng 7 mật mã Caesar) cho bản mã ở Hình 1, việc tìm khóa khá dễ dàng. Thám mã sẽ so sánh giá trị thống kê Khi bình phương của dãy phá mã với giá trị phân phối tần số xuất hiện chữ cái tiếng Anh.
Lập chuỗi chữ cái lấy từ các vị trí 1, 8, 15, 22,… của bản mã ở Hình 1 (vurzjugrggugvgjqkeoagugkkqvwqp…). Đây là chuỗi được mã hóa với cùng một mật mã Caesar.
Giải mã chuỗi này với cả 26 mật mã Caesar có thể, lập bảng so sánh phân phối tần số của văn bản được giải mã với phân phối tần số tiếng Anh cho mỗi khóa. Tương ứng, sẽ thu được 26 giá trị thống kê Khi bình phương. Khóa chính xác sẽ tương ứng với văn bản được giải mã với thống kê Khi bình phương thấp nhất. Kết quả cụ thể như Hình 4 đã tìm được chữ cái khóa đầu tiên, theo đó giá trị Khi bình phương nhỏ nhất là 41.22, tương ứng với khóa là 2 (chữ cái ‘c’).

Hình 4. Giá trị thống kê Khi bình phương của chuỗi giải mã
Tiếp tục tìm 6 chữ cái khóa còn lại theo cách cực tiểu Khi bình phương tương tự để tìm các khóa tương ứng sẽ thu được chuỗi khóa 2,8,0,7,4,17,18. Chuyển về dạng chữ cái là chuỗi 'CIAHERS', chuỗi khóa này bị sai một vị trí. Điều này cho thấy không thể hoàn toàn dựa vào kỹ thuật thám mã này trừ khi thu được bản mã đủ dài. Khóa chính xác trong trường hợp này là 'CIPHERS' và thực tế kiểm tra Khi bình phương có hai giá trị rất thấp cho dãy con thứ 3. Thật không may, giá trị nhỏ nhất lại không đúng, giá trị khóa đúng có giá trị Khi bình phương lớn hơn giá trị nhỏ nhất một chút.
Thực tế trong kiểm tra Khi bình phương cũng như I.C, xác suất xuất hiện của các chữ cái không phải luôn luôn đúng, chúng gần đúng. Hơn nữa, tần số của các chữ cái trong bản mã không phản ánh chính xác phân phối xác suất các chữ cái trên văn bản mã. Đó là lý do kết quả trên cho ra chữ khóa ‘A’ mà lẽ ra phải là ‘P’. Do đó, việc xem xét thêm các khía cạnh khác như là dựa vào quy luật ngôn ngữ để chỉnh sửa kết quả là rất cần thiết.
|
TÀI LIỆU THAM KHẢO [1] Dr. S.B. Sadkhan, Cryptanalysis of a Vigenère, Security of Networks, 2011-2012 [2] Chris Christensen, Cryptanalysis of the Vigenère Cipher: The Friedman Test, Spring 2015, MAT/ CSC 483 [3] Jonathan Taylor, Lecture # 4 – Vigenère Cipher –Kasiski Attack, Statistics 116-Fall 2002 [4] Author: Jeremy Druin, Learning Cryptography by Doing It Wrong: Cryptanalysis of the Vigenère Cipher, [email protected], Advisor: Christopher Walker, CISSP, CCISO, GCED, GWEB, Accepted: 2/1/2018 [5] //shodhganga.inflibnet.ac.in/ bitstream/10603/26543/10/10_chapter5.pdf, CRYPTANALYSIS OF VIGENÈRE CIPHER AND SUBSTITUTION CIPHER [6] S. S. Omran A. S. Al-Khalid D. M. Al-Saady, A Cryptanalytic Attack on Vigenère Cipher Using Genetic Algorithm, 2011 IEEE Conference on Open Systems (ICOS2011), September 25 - 28, 2011, Langkawi, Malaysia [7] Mehmet E. Dalkilic and Cengiz Gungor, An Interactive Cryptanalysis Algorithm for the Vigenère Cipher, Ege University, International Computer Institute Bornova 35100 Izmir, TURKEY, fdalkilic,[email protected] |
TS. Nguyễn Ngọc Cương

08:00 | 30/03/2020

16:00 | 31/03/2020

09:00 | 10/03/2021

08:00 | 06/03/2020

19:00 | 31/12/2018

09:00 | 08/03/2024
Từ lâu, botnet là một trong những mối đe dọa lớn nhất đối với an ninh mạng, nó đã gây ra nhiều thiệt hại cho các tổ chức và doanh nghiệp trên toàn thế giới. Bài báo sẽ giới thiệu tới độc giả một số kỹ thuật phát hiện botnet bằng Honeynet và tính hiệu quả của chúng, đồng thời đề xuất một số hướng phát triển trong tương lai để nâng cao khả năng phát hiện và ngăn chặn botnet bằng Honeynet.

10:00 | 15/09/2023
Thư rác hay email spam là một vấn nạn lớn hiện nay, chúng đã xuất hiện từ rất lâu cùng với sự phát triển của Internet và không chỉ gây phiền nhiễu, tốn thời gian mà còn có thể chứa một số nội dung nguy hiểm. Ước tính có tới 94% phần mềm độc hại được phân phối dưới dạng email spam, một số nguy cơ tiềm ẩn khác bao gồm phần mềm gián điệp, lừa đảo và mã độc tống tiền. Trong bài viết này sẽ thông tin đến bạn đọc cách nhận biết thư rác và ngăn chặn thư rác không mong muốn.

09:00 | 05/06/2023
Tấn công tiêm lỗi (Fault Injection Attack - FIA) là loại tấn công chủ động, giúp tin tặc xâm nhập vào các thiết bị điện tử, mạch tích hợp cũng như các thiết bị mật mã nhằm thu được khóa bí mật và đánh cắp thông tin. Tiêm lỗi có thể được thực hiện trong cả phần cứng và phần mềm. Bài báo này nhóm tác giả sẽ trình bày về các kỹ thuật, công cụ được thực hiện trong FIA.

10:00 | 25/04/2023
HTTP và HTTPS là những giao thức ứng dụng có lịch sử lâu đời của bộ giao thức TCP/IP, thực hiện truyền tải siêu văn bản, được sử dụng chính trên nền tảng mạng lưới toàn cầu (World Wide Web) của Internet. Những năm gần đây, Google đã nghiên cứu thử nghiệm một giao thức mạng mới trong giao thức HTTP phiên bản 3 đặt tên là QUIC, với mục tiêu sẽ dần thay thế TCP và TLS trên web. Bài báo này giới thiệu về giao thức QUIC với các cải tiến trong thiết kế để tăng tốc lưu lượng cũng như làm cho giao thức HTTP có độ bảo mật tốt hơn.
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng

Cùng với sự phát triển của khoa học kỹ thuật có ngày càng nhiều những cuộc tấn công vào phần cứng và gây ra nhiều hậu quả nghiêm trọng. Nhiều giải pháp để bảo vệ phần cứng được đưa ra, trong đó, hàm không thể sao chép vật lý PUF (Physically Unclonable Functions) đang nổi lên như là một trong số những giải pháp bảo mật phần cứng rất triển vọng mạnh mẽ. RO-PUF (Ring Oscillator Physically Unclonable Function) là một kỹ thuật thiết kế PUF nội tại điển hình trong xác thực hay định danh chính xác thiết bị. Bài báo sẽ trình bày một mô hình ứng dụng RO-PUF và chứng minh tính năng xác thực của PUF trong bảo vệ phần cứng FPGA.
10:00 | 13/05/2024

Mã độc không sử dụng tệp (fileless malware hay mã độc fileless) còn có tên gọi khác là “non-malware”, “memory-based malware”. Đây là mối đe dọa không xuất hiện ở một tệp cụ thể, mà thường nằm ở các đoạn mã được lưu trữ trên RAM, do vậy các phần mềm anti-virus hầu như không thể phát hiện được. Thay vào đó, kẻ tấn công sử dụng các kỹ thuật như tiêm lỗi vào bộ nhớ, lợi dụng các công cụ hệ thống tích hợp và sử dụng các ngôn ngữ kịch bản để thực hiện các hoạt động độc hại trực tiếp trong bộ nhớ của hệ thống. Bài báo tìm hiểu về hình thức tấn công bằng mã độc fileless và đề xuất một số giải pháp phòng chống mối đe dọa tinh vi này.
10:00 | 17/05/2024












